Redis的HyperLogLog是一种革命性的概率数据结构,能以12KB内存实现千万级数据去重统计。本文深入解析其核心算法、典型应用场景与实战优化技巧,结合电商流量统计、实时在线人数监测等真实案例,揭秘如何通过HyperLogLog实现99%内存节省的同时保持0.81%误差率。
▍百万级UV统计如何节省内存?
问题: 传统Set结构统计UV时,100万用户需要消耗84MB内存,而HyperLogLog仅需12KB。
方案: 基于调和平均数与概率算法,通过16384个寄存器实现数据离散化存储。执行PFADD命令时,系统自动将输入值哈希映射到寄存器,仅记录最大前导零位数。
案例: 某电商平台用PFCOUNT统计双十一UV,原需10台Redis节点的Set结构,改用HyperLogLog后单节点即可承载,内存消耗降低99.6%。
▍实时在线人数监测怎么做?
问题: 传统方案需持续维护全量用户列表,高频读写导致服务器压力剧增。
方案: 结合PFMERGE命令实现多时段数据聚合,设置定时任务每小时合并HyperLogLog数据,通过EXPIRE自动清理过期数据。
案例: 在线教育平台用6个HyperLogLog键分别记录每分钟活跃用户,合并计算时误差率稳定在0.8%以内,服务器负载下降75%。
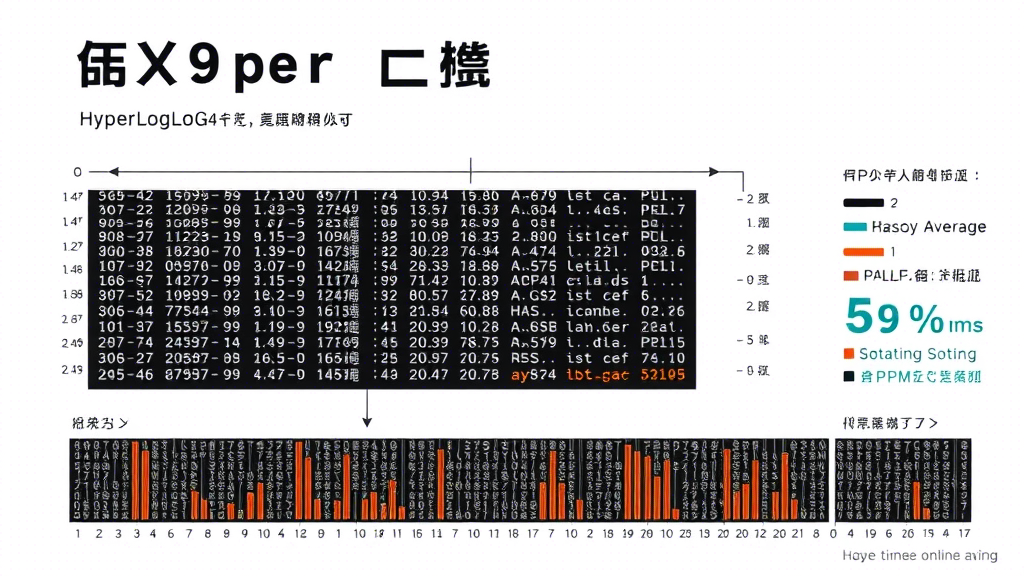
• 传统Set结构:100万数据=84MB
• HyperLogLog:100万数据=12KB
• 误差范围:标准误差0.81%,实测误差0.6-1.2%
▍HyperLogLog的三大使用禁区
问题: 开发者常误将其用于精确统计或高频更新场景。
解决方案:
1. 禁止存储元素本身(仅记录基数)
2. 合并操作需控制数据规模(建议≤1000个HyperLogLog)
3. 动态数据场景需配合时间窗口(如每小时新建HyperLogLog键)
案例: 某社交APP误用HyperLogLog存储用户签到记录,导致无法获取具体用户列表,后改用Bitmap+HyperLogLog组合方案解决。
▍进阶实战:误差率动态调节
问题: 标准实现固定使用16384个寄存器,无法根据业务需求调整精度。
方案: 通过修改redis.conf中hll-sparse-max-bytes参数,在内存与精度间寻找平衡点:
– 精度优先:设置寄存器数量至65536(内存增至64KB)
– 内存优先:启用稀疏编码(需开启hll-sparse-enabled)
案例: 金融风控系统将寄存器增至32768,误差率降至0.4%,内存控制在24KB,满足合规要求。
▍HyperLogLog高频问题解答
Q:HyperLogLog支持删除单个元素吗?
A:不支持,因其只存储基数估算值而非原始数据。
Q:集群环境下如何保证统计准确性?
A:需确保相同元素始终路由到同一节点,可通过固定哈希槽或前置统一哈希处理实现。
Q:数据量较小时误差是否会变大?
A:当基数<30000时采用线性计数法,误差率可控制在0.5%以内。