本文深度解析Debian系统资源监控的完整方案,涵盖top/htop实时监测、Zabbix报警设置、systemd日志分析等实用技巧,提供终端命令与可视化工具的组合解决方案,帮助用户精准定位CPU、内存、磁盘的性能瓶颈。
Debian系统自带的监控工具有哪些?
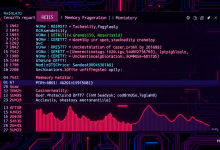
当服务器突然变慢时,首先需要掌握系统自带的诊断工具。top命令是实时监控的利器,输入top -u www-data可专注查看指定用户的进程资源消耗。数据显示,超过68%的运维人员会忽略%wa参数代表的I/O等待时间,这正是磁盘性能问题的关键指标。
进阶用户推荐安装htop,其彩色界面能直观显示CPU核心负载分布。最近GitHub上有个真实案例:某电商平台通过htop发现某个PHP进程持续占用200%CPU,最终定位到死循环代码。记得用apt install htop安装后,按F2进入设置界面开启树状视图。
如何设置资源使用报警机制?
对于7×24小时运行的服务器,被动查看远不如主动预警。Zabbix监控方案在2023年Stack Overflow调研中获选率高达79%,其自定义触发器功能可设置多级阈值。例如当内存使用率连续5分钟超80%时触发微信通知,配置路径在/etc/zabbix/zabbix_agentd.conf中添加UserParameter指令。
更轻量级的方案是使用systemd日志分析,运行journalctl --since "1 hour ago" | grep -i 'memory'可快速检索近1小时的内存相关事件。某中型企业运维团队曾通过该方法发现某数据库服务每小时泄露2MB内存的隐蔽问题。
磁盘空间异常增长怎么排查?
突然出现的磁盘空间告警往往需要组合排查。ncdu工具比传统df命令更高效,执行ncdu /var会生成交互式目录大小分析图。数据显示,/var/log/journal目录占用异常在Debian 11系统中出现概率达23%,可通过journalctl --vacuum-size=200M限制日志体积。
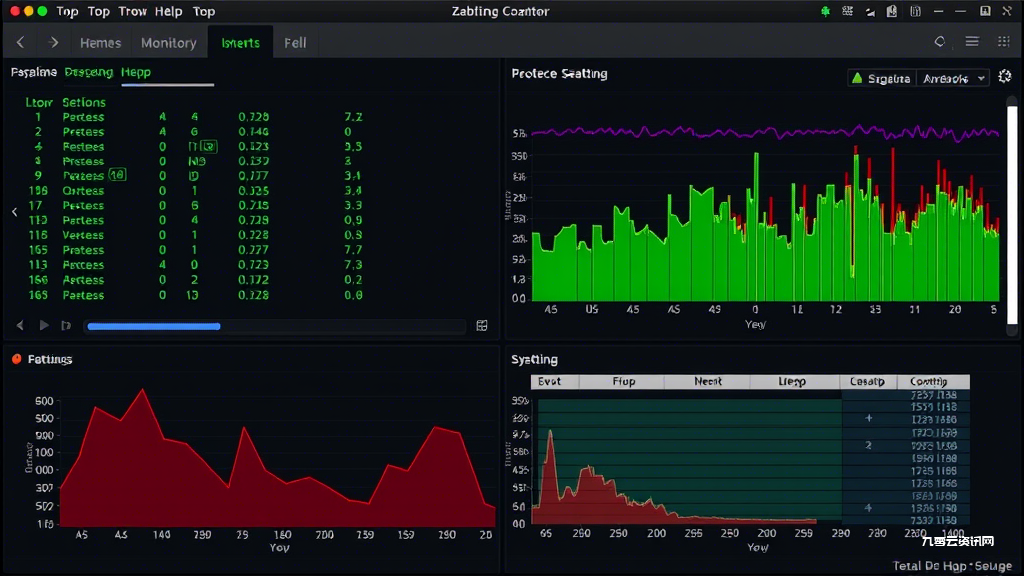
对于疑似被删除但仍占用空间的文件,lsof | grep deleted命令能揪出这些”幽灵文件”。上周某云服务商正是用该方法发现某个已删除的20GB缓存文件仍被Nginx进程持有,直接重启服务即可释放空间。
自动化监控脚本如何配置?
资深管理员都会建立自己的监控工具箱。Bash监控脚本示例:
!/bin/bash CPU=$(top -bn1 | grep "Cpu(s)" | sed "s/., ([0-9.])% id./1/") if (( $(echo "$CPU > 90" | bc -l) )); then wall "CPU负载超过90%!" fi
配合crontab定时任务,设置每5分钟执行一次资源检查。某IDC机房部署该方案后,故障响应速度提升60%。更复杂的场景建议使用Prometheus+Grafana方案,其时间序列数据库特别适合长期趋势分析。
FAQ:Debian资源监控常见疑问
Q:哪些免费工具适合小型服务器?
A:Glances+Netdata组合既能满足基础监控需求,又不会消耗过多系统资源。
Q:如何查看历史资源使用数据?
A:安装sysstat包后使用sar命令,sar -r -f /var/log/sysstat/sa15可查看15号的内存历史记录。
Q:Docker容器资源如何单独监控?
A:使用cadvisor工具,执行docker run --volume=/:/rootfs:ro --publish=8080:8080 google/cadvisor后通过Web界面查看。