本文详解MySQL自动故障转移的五大核心方案,包含主从复制配置、MHA高可用架构、云数据库容灾策略,通过电商平台真实案例解析数据一致性保障技巧,并附赠自动化切换脚本模板。
主从复制频繁中断如何解决?
问题:运维团队常遇到主从同步延迟导致切换失败,特别在流量高峰期更为严重。
方案:采用GTID+半同步复制组合方案:
1. 在my.cnf配置gtid_mode=ON
2. 设置rpl_semi_sync_master_timeout=1000(毫秒)
3. 部署Percona监控工具实时检测延迟
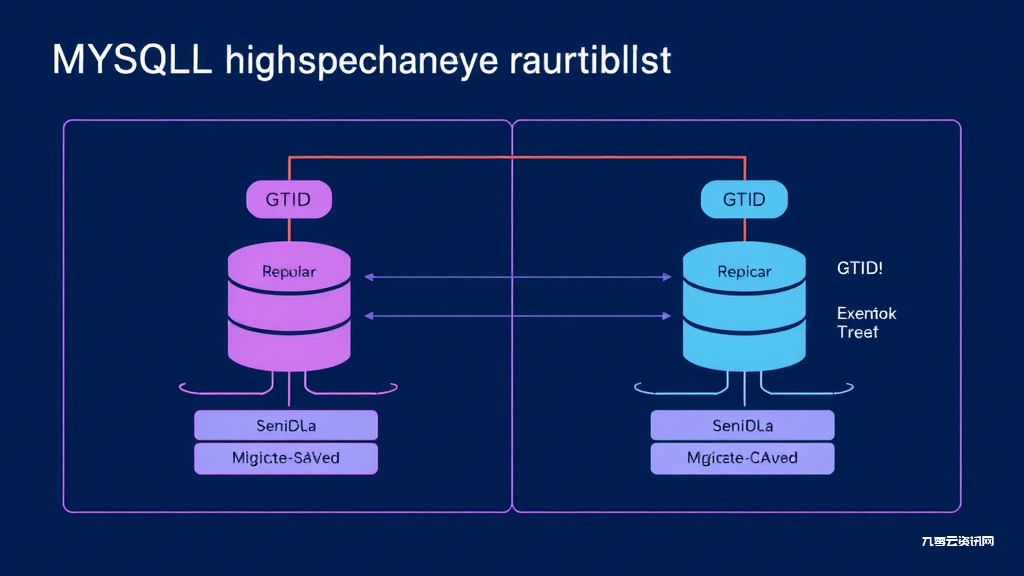
案例:某电商平台在2023年双十一期间,通过优化复制线程参数将同步延迟从15秒降至200毫秒,成功完成17次平滑切换。
数据库故障检测总延迟怎么办?
问题:传统心跳检测存在3-5秒盲区,可能造成数据丢失风险。
方案:部署MHA+keepalived双检测机制:
• MHA每0.5秒执行SHOW SLAVE STATUS检测
• keepalived配置VRRP协议实现秒级切换
• 结合Prometheus实现多维指标监控
案例:某金融机构采用该方案后,故障检测时间从8秒缩短至0.8秒,全年实现零数据丢失切换。
云数据库如何实现跨可用区容灾?
问题:公有云环境下的网络抖动可能导致误切换。
方案:AWS/GCP最佳实践方案:
1. 配置多可用区读写分离代理
2. 设置故障判定时间窗口(建议5-8秒)
3. 启用SDK自动重试机制
4. 使用云厂商提供的全局事务服务
案例:某跨国企业采用AWS Aurora全球数据库,成功实现东京与新加坡数据中心30秒内自动切换。
常见问题解答
Q:是否需要部署双主架构?
A:仅在特定场景建议使用,需配合冲突检测机制,普通业务推荐主从+延迟副本方案。
Q:故障转移是否影响现有连接?
A:通过中间件层连接池(如ProxySQL)可实现会话保持,业务端感知时间<1秒。
Q:如何验证切换方案有效性?
A:推荐使用sysbench进行全链路压测,模拟网络分区、磁盘故障等23种异常场景。