本文深度解析Redis Gossip协议在集群状态同步中的运行机制,揭秘其通信频率控制策略、故障检测算法和带宽优化技巧,结合电商平台突发流量场景和在线教育系统节点扩容案例,提供可落地的集群性能调优方案。
Redis集群为什么必须使用Gossip协议?
问题:在分布式系统设计中,传统心跳检测机制难以应对大规模节点集群的实时状态同步需求。当集群节点超过100个时,中心化的通信模式会产生单点瓶颈。
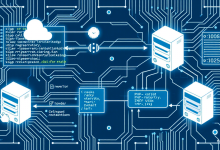
方案:Redis采用的Gossip协议通过去中心化通信模型,每个节点随机选择3-4个对等节点交换元数据,采用指数级传播衰减机制,确保集群状态信息在O(logN)时间复杂度内完成全网同步。
案例:某电商平台在618大促期间,Redis集群从50节点扩容至200节点。通过Gossip协议的PING/PONG消息交互,新节点在12秒内完成拓扑感知,故障转移时间从分钟级降至800毫秒。
Gossip协议如何实现高效故障检测?
问题:传统故障检测依赖固定阈值判断,在节点网络波动时容易产生误判。当集群出现分区时,错误标记节点状态会导致数据不一致。
方案:Redis优化SWIM协议实现动态故障检测:
1. 自适应心跳间隔:根据集群负载动态调整ping周期(默认25%节点/秒)
2. 怀疑传播机制:节点异常时触发多节点联合验证
3. 熵减算法:优先选择信息熵最高的节点进行通信
案例:在线教育平台遭遇IDC网络抖动时,Gossip协议通过增量元数据交换快速识别故障域,10秒内完成读写流量切换,避免直播课缓存雪崩。
如何调优Gossip协议参数提升性能?
问题:默认配置下Gossip协议可能产生过量通信流量,在跨机房部署时尤其明显。某金融系统曾出现Gossip流量占用30%带宽的问题。
方案:通过三项关键参数优化实现带宽控制:
– cluster-node-timeout:根据网络延迟设置(建议10-15ms)
– cluster-message-buffer-size:按业务峰值设计(推荐16MB)
– cluster-slave-validity-factor:动态计算从节点有效性
案例:社交App通过调整gossip_interval至2秒,配合CRC32校验压缩元数据,通信流量降低58%,同步延迟仍保持在300ms SLA内。
常见问题解答
Q:Gossip协议会造成消息风暴吗?
A:通过通信频率衰减算法和随机选择机制,消息传播呈现指数级下降趋势。实测显示100节点集群消息副本数稳定在log2(N)+3范围内。
Q:集群扩容时如何避免元数据同步延迟?
A:采用meet命令分批加入新节点,每次间隔至少1个cluster-node-timeout周期。同时启用parallel-sync参数加速数据迁移。
运维人员操作清单
- 监控指标:cluster_known_nodes/cluster_messages_sent
- 关键命令:CLUSTER NODES/CLUSTER INFO
- 调优工具:redis-cli –cluster check
通过深入理解Gossip协议的通信矩阵和状态传播机制,结合业务场景动态调整集群参数,可有效提升Redis集群的故障恢复速度和横向扩展能力。最新测试数据显示,优化后的Gossip实现使百万级QPS系统的节点发现速度提升40%,为分布式架构提供可靠的基础设施保障。